
If you’re passionate about Java, you should get to know the Collections Framework.
If you’re passionate about Java, you should get to know the Collections Framework.
let's do a cross section of Collections Framework. ✂️
Collection: group of objects contained in a single object.
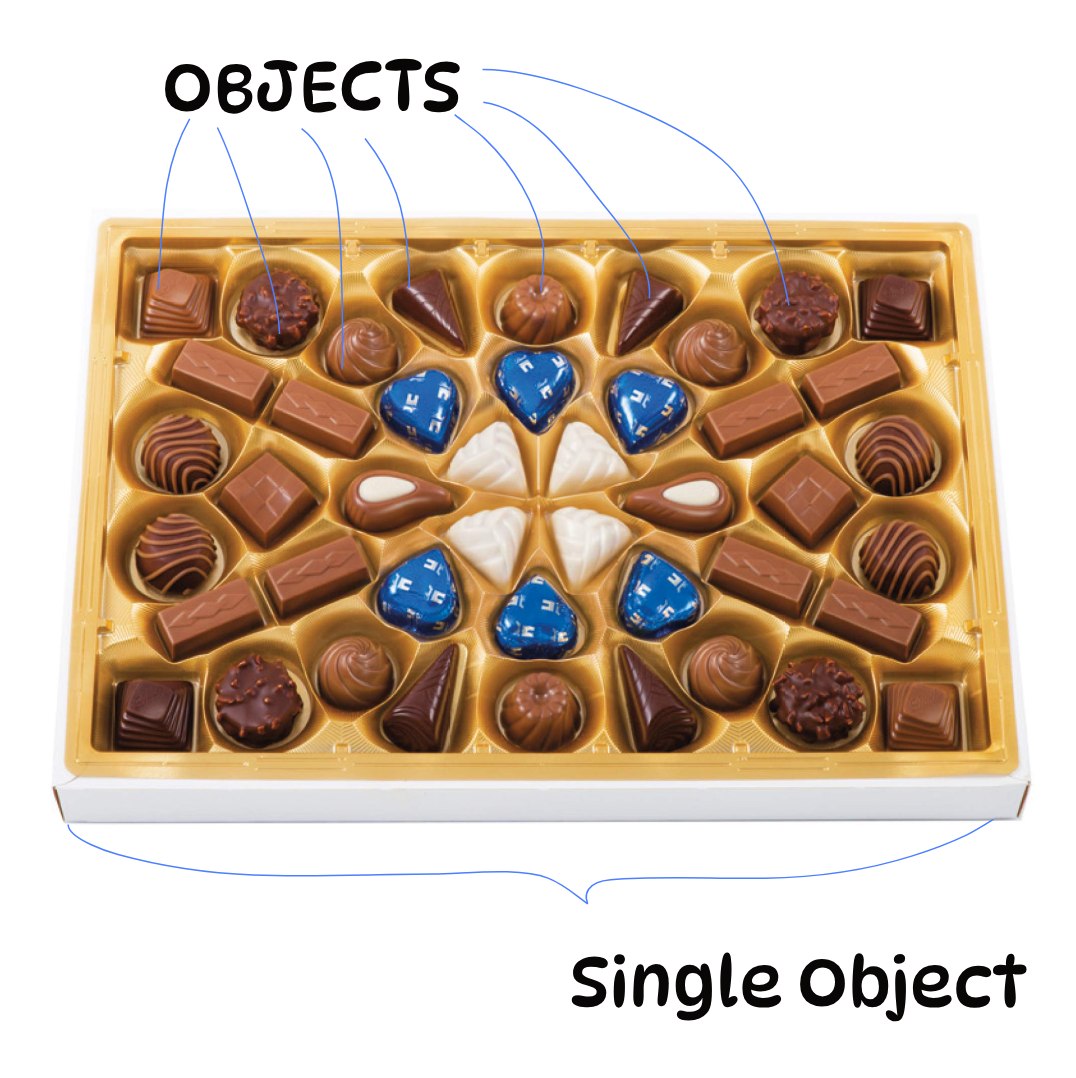
Framework: set of classes in java.util for storing collections
Now you got the basic idea, right.
There are four main interfaces in the Java Collections Framework.
-
List
-
Set
-
Queue, Deque
-
Map
Note the point, these these interfaces form the basis of the framework.
Look at the following image and understand how they are related.

Iterable is the parent of Collection, so we can say that Collection inherits all the behavior of Iterable. Think of Collection and Map . While they're not directly related in terms of inheritance, they have distinct roles in the Java Collections Framework. Collection , manages individual elements, while Map , handles key-value pairs. Together, they contribute to the efficient organization and management of data in Java programs. Additionally, Collection has three children: List, Set, and Queue (with Deque as another child of Queue), each with their unique traits.
Let's describe their characters .
List : ordered collection of objects that allow duplicate entries, objects in list can be accessed by an int index.
Set: is a collection that does not allow duplicate entries.
Queue: is a collection that orders its objects in a specific order for processing.
Deque: is a subinterface of Queue that allows access at both ends.
Map: is a collection that map keys to values, with no duplicate keys allowed.
Why am I telling you that a map is a collection? In the above image, you can see that a map does not extend from the Collection interface. However, here’s something you need to know: Map in Java does not directly extend from the Collection interface. Still, it is considered part of the broader Java Collections Framework due to its association with collections and its similar use in organizing and managing data.
Now, you may be wondering how to choose an Interface. I will provide you with a basic decision flowchart, just to give you an idea.
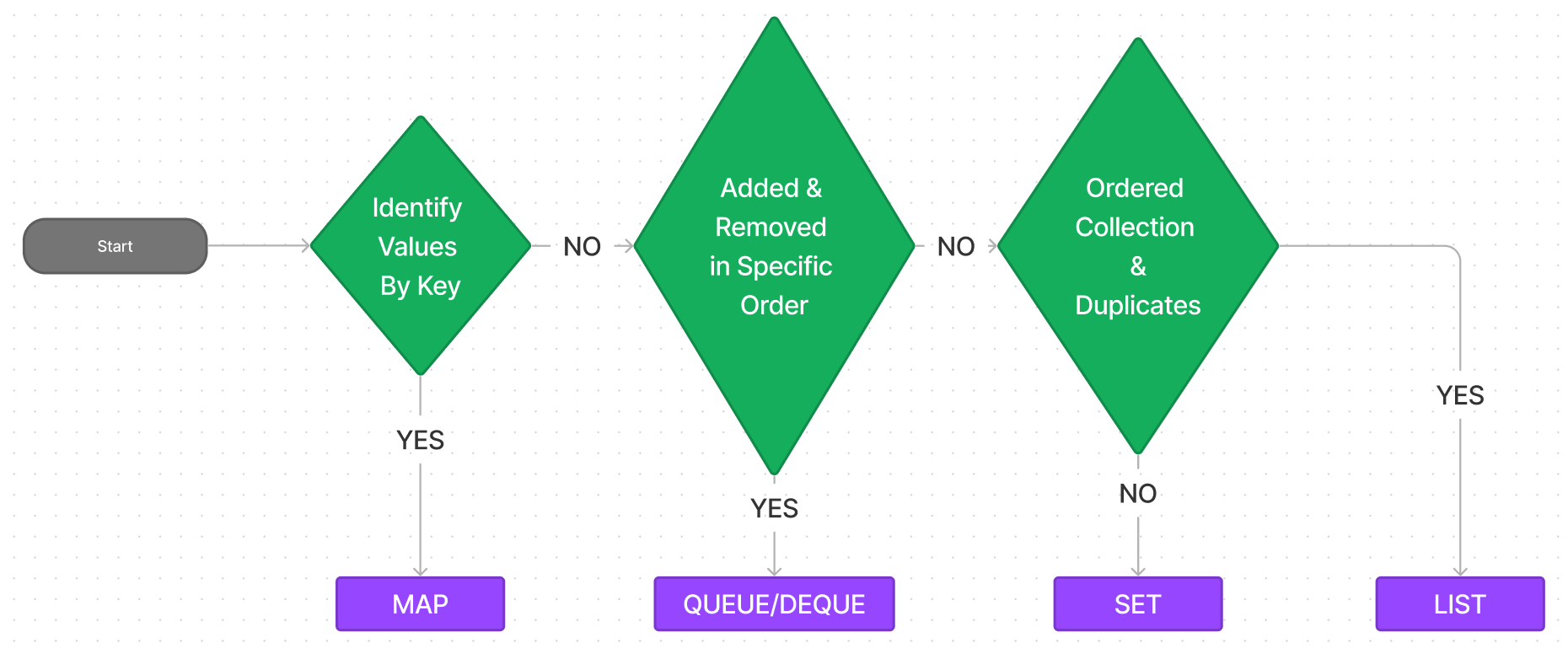
Now let's dive bit deeper.
Before moving on you need to know something:
Interfaces serve as contracts in Java. Classes that voluntarily choose to implement these interfaces are obligated to override, which means they must provide concrete implementations for the methods declared within those interfaces.
Mastering the Collections Framework in Java can be simplified by understanding the “contracts” or interfaces. By familiarizing yourself with the abstract methods defined in these interfaces, you gain insight into the concrete methods present in classes that implement these interfaces. It’s important to remember that classes can also have their own concrete methods.
Create a mental map to visualize these relationships. You don’t need to memorize every method, but it’s beneficial to be acquainted with the most commonly used ones.
This knowledge can be a valuable asset in interviews and coding challenges. Think of these methods as shortcuts — while you can complete tasks without them, those who know these shortcuts can complete tasks faster and have more fun doing it. In the following paragraphs, I’ll introduce you to some commonly used classes and their concrete methods.
Let’s get to know the Iterable Interface.
Abstract Method:
- iterator
Default Methods:
-
forEach
-
spliterator
What does it mean? Since Iterable is a superinterface, classes that implement it or any of its subinterfaces need to provide an implementation for the abstract method iterator(). However, classes that implement Iterable are not required to implement the default methods forEach and spliterator() because default methods provide a default implementation in the interface itself, which can be optionally overridden by the implementing classes if they have specific requirements.
Now let’s move on to the Collection Interface.
Abstract Method:
-
add
-
addAll
-
clear
-
contains
-
containsAll
-
equals
-
hashCode
-
isEmpty
-
iterator This method is a redeclaration of iterator method in Iterable Interface, why? because the Collection interface's iterator method provides more information about the behavior of the iterator in the context of collections. when a subinterface (in this case, Collection) redeclares a method that is already declared in a superinterface (in this case, Iterable), the redeclaration in the subinterface effectively "hides" the method from the perspective of classes or interfaces that implement or extend the subinterface. It makes the contract more explicit and clear, especially for developers who might not be fully aware of the inheritance hierarchy.
-
remove
-
removeAll
-
retainAll
-
size
-
toArray
-
toArray
Object[] array = stringCollection.toArray();
String[] array = new String[stringCollection.size()];
array = stringCollection.toArray(array);
Both versions of the toArray method convert the elements from the collection into an array, but the second version allows you to specify the desired array type and reuse an existing array if it's large enough. This can help you work with the desired array type and potentially save on memory allocation when converting elements.
Default Methods:
-
parallelStream
-
removeIf
-
spliterator
-
stream
-
toArray
//default <T> T[] toArray([IntFunction]<T[]> generator)
@FunctionalInterface
public interface IntFunction<T[]>
T[] apply(int value);
This is a functional interface because it has only one abstract method, apply(int value), which takes an integer as an argument and returns an array of type T[]. The apply method is responsible for creating and returning the array with the specified length.
Here’s an example using toArray and an IntFunction:
Collection<String> stringCollection = Arrays.asList("Alice", "Bob", "Charlie");
String[] newArray = stringCollection.toArray(length -> new String[length]);
This allows you to customize how the array is created when using methods that require an IntFunction, such as toArray, giving you more control over the type and size of the resulting array.
Great! Now, I’d like to emphasize an important point to remember. All of the methods we have discussed so far must be implemented by the classes that are bound by contracts with these interfaces.
General-purpose implementations
These are the primary implementations of the collection interfaces. While there are other implementations like Legacy, Special-purpose, so and so.. it’s important to note that, as of the latest Java version (Java 19), every Java developer ‘should’ be familiar with the following General-purpose implementations. These implementations are designed to be versatile and suitable for a wide range of common use cases.*

Hey, look at the first row of the table. Now, you may be thinking, ‘What are Hash Table, Resizable Array, Balanced Tree, and Linked List?’ No more confusion — these are data structures used to create different implementations for our beloved interfaces.
I will write separate blogs on these data structures, so stay tuned.
List — Interface
There are approximately 41 methods in the List Interface, and some of them are redeclarations. Now, you have an understanding of why redeclarations are necessary.
Following are the classes that implement the List Interface, which means these classes have implementations for the methods that we have seen so far.
-
ArrayList — Class
-
LinkedList — Class
When to use List?
If you an ordered collection that can contain duplicate entries.
ArrayList
-
An ArrayList is like a resizable array. When elements are added, the ArrayList automatically grows. When you aren’t sure which collection to use, use an ArrayList.
-
Look up any element in constant time.
-
Adding or removing an element is slower than accessing an element.
-
If you read more and write less use ArrayList.
How to create ArrayList?
Syntax:
ArrayList<DataType> arrayListName = new ArrayList<DataType>();
What are some common methods used with ArrayLists? There are many methods available, but I will mention some of the most commonly used ones.
-
add(E element) and add(int index, E element) : Adding elements to an ArrayList is a common operation, especially when building lists incrementally or inserting elements at specific positions.
-
get(int index): Accessing elements by index is crucial for retrieving or manipulating specific values.
-
remove(int index): and remove(Object o): Removing elements is frequently needed to modify the ArrayList's content.
-
size(): You may need to check the size of the ArrayList to control loops and conditionals.
-
isEmpty(): Verifying if the ArrayList is empty is often used to handle edge cases.
-
toArray(): Converting the ArrayList to an array is sometimes necessary, especially if the problem specifies a different output format.
-
indexOf(Object o) and lastIndexOf(Object o): These methods help you find the position of a specific element, which can be valuable in various scenarios.
-
subList(int fromIndex, int toIndex): When working with a specific portion of the ArrayList, this method can simplify the process.
LinkedList
-
A LinkedList is special because it implements both List and Deque.
-
The main benefits of a LinkedList are that you can access, add to, and remove from the beginning and end of the list in constant time.
-
The trade-off is that dealing with an arbitrary index takes linear time.
-
LinkedList a good choice when you’ll be using it as Deque.
How to create LinkedList?
Syntax:
LinkedList<DataType> linkedListName = new LinkedList<DataType>();
What are some common methods used with LinkedList? There are many methods available, but I will mention some of the most commonly used ones.
-
add and add(int index, E element): Adding elements to the LinkedList, either at the end or at a specific index.
-
get: Accessing elements by index to retrieve the value at a particular position.
-
remove and remove(Object o): Removing elements by index or by a specified value.
-
size: Determining the size (number of elements) of the LinkedList.
-
isEmpty: Checking if the LinkedList is empty.
-
clear: Removing all elements from the LinkedList.
-
indexOf and lastIndexOf(Object o): Finding the index of the first or last occurrence of a specified element.
-
toArray: Converting the LinkedList to an array.
-
contains: Checking if the LinkedList contains a specific element.
-
addFirst and addLast: Adding elements to the beginning or end of the LinkedList.
-
getFirst and getLast: Retrieving the first and last elements of the LinkedList.
-
removeFirst and removeLast: Removing the first and last elements of the LinkedList.
Set — Interface
-
HashSet — Class
-
TreeSet — Class
-
LinkedHashSet — Class
When to use Set?
You use a Set when you don’t want to allow duplicate entries.
HashSet
-
Keys are a hash and the values are an Object.
-
HashSet uses the hashCode() method of the objects to retrieve them more efficiently.
-
The main benefit is that adding elements and checking whether an element is in the set both have constant time.
-
The trade-off is that you lose the order in which you inserted the elements.
How to create HashSet?
Syntax:
HashSet<DataType> hashSetName = new HashSet<DataType>();
What are some common methods used with HashSet? There are many methods available, but I will mention some of the most commonly used ones.
-
add(E e): Adds the specified element to the HashSet if it is not already present. Returns true if the element was added (i.e., it was not already in the set).
-
remove(Object o): Removes the specified element from the HashSet if it is present. Returns true if the element was removed.
-
contains(Object o): Checks if the HashSet contains the specified element. Returns true if the element is found.
-
isEmpty(): Checks if the HashSet is empty (contains no elements). Returns true if the HashSet is empty.
-
size(): Returns the number of elements in the HashSet.
-
clear(): Removes all elements from the HashSet, making it empty.
-
iterator(): Returns an iterator over the elements in the HashSet. You can use this iterator to loop through the elements in the set.
-
addAll: Adds all elements from a collection c into the HashSet.
-
removeAll: Removes all elements from the HashSet that are also contained in the specified collection c.
-
retainAll: Removes all elements from the HashSet that are not contained in the specified collection c.
-
toArray(): Converts the HashSet into an array.
-
hashCode(): Returns the hash code value for the HashSet. This is useful when you need to compare two HashSets for equality.
-
equals(Object o): Compares the HashSet with another object to check for equality.
TreeSet
-
A TreeSet stores its elements in a sorted tree structure.
-
The main benefit is that the set is always in sorted order.
-
The trade-off is that adding and checking whether an element exists takes longer than with a HashSet, especially as the tree grows larger.
How to create TreeSet?
Syntax:
TreeSet<DataType> treeSetName = new TreeSet<DataType>();
What are some common methods used with TreeSet? There are many methods available, but I will mention some of the most commonly used ones.
-
add(E e): Adds the specified element to the TreeSet if it is not already present. Returns true if the element was added (i.e., it was not already in the set).
-
remove(Object o): Removes the specified element from the TreeSet if it is present. Returns true if the element was removed.
-
contains(Object o): Checks if the TreeSet contains the specified element. Returns true if the element is found.
-
isEmpty(): Checks if the TreeSet is empty (contains no elements). Returns true if the TreeSet is empty.
-
size(): Returns the number of elements in the TreeSet.
-
clear(): Removes all elements from the TreeSet, making it empty.
-
iterator(): Returns an iterator over the elements in the TreeSet. You can use this iterator to loop through the elements in sorted order.
-
first(): Returns the first (lowest) element in the TreeSet.
-
last(): Returns the last (highest) element in the TreeSet.
LinkedHashSet
-
Maintains the order of elements in which they were inserted.
-
Internally, LinkedHashSet is implemented as a combination of a hash table and a linked list. The hash table provides fast access to elements, while the linked list maintains the order of insertion.
-
LinkedHashSet does not allow null elements.
-
Lookup times are slightly slower than HashSet, faster than TreeSet.
-
Used when you need a Set with both uniqueness and a predictable order.
How to create LinkedHashSet?
Syntax:
LinkedHashSet<DataType> linkedHashSetName = new LinkedHashSet<DataType>();
What are some common methods used with LinkedHashSet? There are many methods available, but I will mention some of the most commonly used ones.
-
add(E e): Adds the specified element to the LinkedHashSet if it is not already present. Returns true if the element was added (i.e., it was not already in the set).
-
remove(Object o): Removes the specified element from the LinkedHashSet if it is present. Returns true if the element was removed.
-
contains(Object o): Checks if the LinkedHashSet contains the specified element. Returns true if the element is found.
-
isEmpty(): Checks if the LinkedHashSet is empty (contains no elements). Returns true if the LinkedHashSet is empty.
-
size(): Returns the number of elements in the LinkedHashSet.
-
clear(): Removes all elements from the LinkedHashSet, making it empty.
-
iterator(): Returns an iterator over the elements in the LinkedHashSet. You can use this iterator to loop through the elements in insertion order.
-
toArray(): Converts the LinkedHashSet into an array.
-
equals(Object o): Compares the LinkedHashSet with another object to check for equality.
-
hashCode(): Returns the hash code value for the LinkedHashSet.
Queue, Deque — Interface
-
ArrayDeque — Class
-
LinkedList — Class
When to use Queue or Deque?
You use a Queue when elements are added and removed in a specific order.
ArrayDeque
-
LinkedList implements both the List and Deque interfaces. You can use the ArrayDeque class if you don’t need the List methods.
-
It can be more memory-efficient than LinkedList for large collections.
How to create ArrayDeque?
Syntax:
ArrayDeque<DataType> dequeName = new ArrayDeque<DataType>();
What are some common methods used with ArrayDeque? There are many methods available, but I will mention some of the most commonly used ones.
-
add(E e) and addFirst(E e): Adds an element to the end (tail) or the beginning (head) of the deque.
-
offer(E e) and offerFirst(E e): Adds an element to the end or the beginning of the deque. They are similar to add(), but they return true if successful and false if the deque is full (in the case of a capacity-constrained deque).
-
remove() and removeFirst(): Removes and returns the first element (head) of the deque. Throws an exception if the deque is empty.
-
poll() and pollFirst(): Removes and returns the first element (head) of the deque, or returns null if the deque is empty.
-
removeLast(): Removes and returns the last element (tail) of the deque. Throws an exception if the deque is empty.
-
pollLast(): Removes and returns the last element (tail) of the deque, or returns null if the deque is empty.
-
getFirst(): Retrieves, but does not remove, the first element (head) of the deque. Throws an exception if the deque is empty.
-
peek() and peekFirst(): Retrieves, but does not remove, the first element (head) of the deque, or returns null if the deque is empty.
-
getLast(): Retrieves, but does not remove, the last element (tail) of the deque. Throws an exception if the deque is empty.
-
peekLast(): Retrieves, but does not remove, the last element (tail) of the deque, or returns null if the deque is empty.
-
size(): Returns the number of elements in the deque.
-
isEmpty(): Checks if the deque is empty and returns true if it is.
-
clear(): Removes all elements from the deque, making it empty.
-
toArray(): Converts the deque into an array.
-
iterator(): Returns an iterator over the elements in the deque.
-
descendingIterator(): Returns an iterator over the elements in reverse order.
LinkedList
-
All the features previously mentioned plus
-
ArrayDeque has fixed capacity and needs to occasionally resize when the capacity is exceeded. LinkedList doesn’t have this limitation, which can be beneficial in situations where the size of the Deque is not known in advance or may change frequently.
How to create Deque with LinkedList?
Syntax:
Deque<DataType> dequeName = new LinkedList<DataType>();
How to create Queue with LinkedList?
Syntax:
Queue<DataType> queueName = new LinkedList<DataType>();
What are some common methods used with LinkedList as Queue/Deque? There are many methods available, but I will mention some of the most commonly used ones.
For Queue (which can be implemented using LinkedList):
-
add(E e) or offer(E e): To add elements to the queue.
-
remove() or poll(): To remove and return the element at the head of the queue.
-
element() or peek(): To retrieve the element at the head of the queue without removing it.
For Deque (Double-ended Queue):
-
addFirst(E e) and addLast(E e): To add elements to the front and back of the deque, respectively.
-
removeFirst() and removeLast(): To remove and return elements from the front and back of the deque, respectively.
-
getFirst() and getLast(): To retrieve the elements at the front and back of the deque without removing them.
-
offerFirst(E e) and offerLast(E e): To add elements to the front and back of the deque if space is available.
-
pollFirst() and pollLast(): To remove and return elements from the front and back of the deque, or return null if the deque is empty.
-
peekFirst() and peekLast(): To retrieve the elements at the front and back of the deque without removing them, or return null if the deque is empty.
Map — Interface
-
HashMap — Class
-
TreeMap — Class
-
LinkedHashMap — Class
When to use Map?
You use a Map when you want to identify values by a key.
HashMap
-
Each element in a HashMap is stored as a key-value pair, where the key is unique and used for retrieval, and the value is associated with that key.
-
HashMap offers constant-time performance for basic operations (e.g., get and put) on average, making it efficient for most use cases.
-
When two keys have the same hash code (collision), HashMap uses a linked list (a bucket) to store multiple key-value pairs with the same hash code.
How to create HashMap?
Syntax:
HashMap<KeyType, ValueType> hashMap = new HashMap<>();
What are some common methods used with HashMap? There are many methods available, but I will mention some of the most commonly used ones.
-
put(K key, V value): Used to insert or update a key-value pair in the HashMap.
-
get(Object key): Retrieves the value associated with a given key.
-
containsKey(Object key): Checks if the HashMap contains a specific key.
-
containsValue(Object value): Checks if the HashMap contains a specific value.
-
remove(Object key): Removes a key-value pair based on the given key.
-
isEmpty(): Checks if the HashMap is empty.
-
size(): Returns the number of key-value pairs in the HashMap.
-
keySet(): Retrieves a set of all keys in the HashMap.
-
values(): Retrieves a collection of all values in the HashMap.
-
entrySet(): Retrieves a set of key-value pairs (entries) in the HashMap.
TreeMap
-
TreeMap maintains its elements in sorted order based on the natural order of keys or a specified comparator.
-
TreeMap does not allow null keys (unlike HashMap). Attempting to insert a null key will result in a NullPointerException.
-
TreeMap is suitable for situations where you need key-value pairs sorted by keys and need efficient lookups, range queries, and ordered traversal.
How to create TreeMap?
Syntax:
TreeMap<KeyType, ValueType> treeMap = new TreeMap<>();
What are some common methods used with TreeMap? There are many methods available, but I will mention some of the most commonly used ones.
-
put(K key, V value): Used to insert or update a key-value pair in the TreeMap.
-
get(Object key): Retrieves the value associated with a given key.
-
remove(Object key): Removes a key-value pair based on the given key.
-
containsKey(Object key): Checks if the TreeMap contains a specific key.
-
isEmpty(): Checks if the TreeMap is empty.
-
size(): Returns the number of key-value pairs in the TreeMap.
-
keySet(): Retrieves a set of all keys in the TreeMap in sorted order.
-
values(): Retrieves a collection of all values in the TreeMap in corresponding sorted order.
-
entrySet(): Retrieves a set of key-value pairs (entries) in the TreeMap in sorted order.
-
firstKey(): Returns the first (lowest) key in the TreeMap.
-
lastKey(): Returns the last (highest) key in the TreeMap.
-
subMap(K fromKey, K toKey): Returns a view of the portion of the TreeMap whose keys range from fromKey (inclusive) to toKey (exclusive).
-
headMap(K toKey): Returns a view of the portion of the TreeMap whose keys are less than toKey.
-
tailMap(K fromKey): Returns a view of the portion of the TreeMap whose keys are greater than or equal to fromKey.
-
clear(): Removes all key-value pairs from the TreeMap.
LinkedHashMap
-
Unlike HashMap, which doesn't guarantee any specific order of elements, LinkedHashMap maintains the order in which elements were inserted.
-
Keys in a LinkedHashMap must be unique. If you attempt to insert a duplicate key, the new value will overwrite the existing one.
-
While LinkedHashMap provides predictable iteration order, it may consume slightly more memory and perform slightly slower than HashMap for certain use cases.
How to create LinkedHashMap?
Syntax:
LinkedHashMap<KeyType, ValueType> linkedHashMap = new LinkedHashMap<>();
What are some common methods used with LinkedHashMap? There are many methods available, but I will mention some of the most commonly used ones.
-
put(K key, V value): Used to insert or update a key-value pair in the LinkedHashMap.
-
get(Object key): Retrieves the value associated with a given key.
-
remove(Object key): Removes a key-value pair based on the given key.
-
containsKey(Object key): Checks if the LinkedHashMap contains a specific key.
-
isEmpty(): Checks if the LinkedHashMap is empty.
-
size(): Returns the number of key-value pairs in the LinkedHashMap.
-
keySet(): Retrieves a set of all keys in the LinkedHashMap in the order of insertion.
-
values(): Retrieves a collection of all values in the LinkedHashMap in the order of insertion.
-
entrySet(): Retrieves a set of key-value pairs (entries) in the LinkedHashMap in the order of insertion.
-
clear(): Removes all key-value pairs from the LinkedHashMap.
-
removeEldestEntry: This method can be overridden to control the removal of the eldest entry when the size of the LinkedHashMap exceeds a specified maximum size. It's often used to implement a cache with a limited size.
-
accessOrder: You can specify whether the LinkedHashMap maintains insertion order (false, default) or access order (true). When in access order mode, elements are reordered based on their access history.
Wow, you did a great job! Now you have an idea of what the Java Collections Framework is.
I hope it was fun 🤩 If you enjoyed the content and would like to show your appreciation, you can support me in two ways:
-
Give it a Clap: Just click on the 👏 button at the end of the article. Each clap is a virtual pat on the back and a way to let me know that you liked the blog.
-
Buy Me a Coffee: If you’re feeling extra generous and would like to support my work further. To leave a tip, simply click on the “Tip” button, and any amount you’re comfortable with is greatly appreciated. Your contribution will keep me fueled and motivated to create more content in the future.
Your support means a lot to me, and it encourages me to continue sharing my knowledge and experiences. I’m grateful for each and every reader who finds value in what I write. 🙏
❤️ Feeling the love? Give me a tip on Medium!